
En este tutorial, vamos a hablar sobre el raspado web con python.
En primer lugar, tenemos que discutir qué es la técnica de raspado web. Cada vez que necesitamos los datos (puede ser texto, imágenes, enlaces y videos) de la web a nuestra base de datos. Discutamos dónde deberíamos necesitar el raspado web en el mundo real.
- Hoy en día, tenemos tantos competidores en todos y cada uno de los campos para superarlos. Necesitamos sus datos del sitio web o Blogs para conocer los productos, los clientes y sus instalaciones.
- Y algunos administradores, el sitio web, los blogs y el canal de youtube quieren las revisiones de sus clientes en la base de datos y desean actualizar con esta In, esta condición usan raspado web
Hay muchas otras áreas donde necesitamos raspado web, Discutimos dos puntos para este artículo para los lectores.
¿Quieres ser certificado como Programador Python? Entonces el curso Intellipaat Python Certification es para usted.
Requisitos previos:
Solo tiene conocimientos básicos de python, prepárese para aprender el raspado web.
¿Qué tecnología deberíamos utilizar para lograr el raspado web?
Podemos hacer esto con JavaScript y python, pero de acuerdo con la mayoría de la gente, podemos hacerlo con python fácilmente, solo debes saber lo básico conocimiento de python, nada más de lo que aprenderemos en este artículo.
Tutorial de raspado web de Python
1. Recuperar enlaces y mensajes de texto del sitio web y el canal de Youtube a través de raspado web
- En este primer punto, aprenderemos cómo obtener el texto y los enlaces de cualquier página web con algunos métodos y clases.
Vamos a hacer esto hermoso método de la sopa.
1. Instale BS4 e instale el analizador lxml
- Para instalar BS4 en windows, abra su indicador de comando o shell de Windows y escriba: pip install bs4
- Para instalar lxml en windows abra su indicador de comando o ventanas shell y tipo: pip install lxml
Nota: "pip no se reconoce" si se produce este error, obtenga ayuda de cualquier referencia.
Para instalar BS4 en ubuntu abra su terminal:
- Si está usando el tipo de versión 2 de python: pip install bs4
- Si está usando el tipo de la versión 3 de python: pip3 install bs4 [1965902626]
Para instalar lxml en ubuntu, abra su terminal
- Si está usando el tipo python versión 2: pip instale lxml
- Si está usando el tipo python versión 3 : pip3 install lxml
2. Abrir Pycharm e importar módulos
Importar módulos útiles:
import bs4
[19659000]] [194590002]
[196590002] módulos útiles ” width=”965″ height=”112″ srcset=”http://bit.ly/2uWPZK5 965w, https://www.thecrazyprogrammer.com/wp-content/uploads/2019/03/Import-useful-modules–300×35.png 300w, https://www.thecrazyprogrammer.com/wp-content/uploads/2019/03/Import-useful-modules–660×77.png 660w” sizes=”(max-width: 965px) 100vw, 965px”/>
Luego tome la url de un sitio web en particular, por ejemplo http://bit.ly/1mqhNt2
|
url = "http://bit.ly/2h392Ps" data = solicita . obtener ( url ) sopa = bs4 . BeautifulSoup . ] ] ] 19659045] 'htm.parser' ) imprimir ( sopa . prettify ) ) ) Y ahora obtendrá el script html con la ayuda de estas líneas de código de enlace particular que proporcionó al programa. Estos son los mismos datos que se encuentran en la fuente de la página web. También puede consultarlos.
Ahora hablamos de encontrar function () con la ayuda de find function podemos obtener el texto, los enlaces y muchas más cosas de nuestra página web. Podemos lograr esto a través del código de Python que está escrito debajo de esta línea: Simplemente tomamos un bucle en nuestro programa y comentamos la línea anterior.
Y obtendremos el primer párrafo de nuestra página web, se puede ver el resultado En la imagen de abajo. Mira, esta es la vista original del sitio web y ver la salida del código de Python en la imagen de abajo.
Pycharm Output
Ahora, si desea todo el párrafo de esta página web, solo necesita hacer algunos cambios en este código, es decir, Aquí, deberíamos usar la función find_all () en lugar de encontrar la función. Hagámoslo prácticamente
Obtendrá todos los párrafos de la página web. Ahora, se producirá un problema que es la etiqueta " ". con los datos de texto para eliminar la etiqueta tenemos que hacer cambios en el código de esta manera:
Simplemente agregamos " .text" en la función de impresión con para. Esto nos dará solo texto sin ninguna etiqueta. Ahora vea la salida allí. La etiqueta se ha eliminado con este código. Con la última línea, hemos completado nuestro primer punto, es decir, cómo podemos obtener los datos (texto) y el script html de nuestra página web. En el segundo punto, aprenderemos cómo obtenemos los hipervínculos de la página web. 2. Cómo obtener todos los enlaces de la página web a través del raspado webIntroducción: En esto, aprenderemos cómo podemos obtener los enlaces de la página web y los canales de youtube o cualquier otra página web que desee. Todos los módulos de importación serán iguales; algunos cambios solo están disponibles, como por ejemplo: Tome uno para el bucle con la condición de la etiqueta de anclaje ' a' y obtenga todos los enlaces usando href y asignelas al objeto (que puede ver en la imagen de abajo) que se tomó debajo del bucle for y luego imprima el objeto. Ahora, obtendrá todos los enlaces de la página web. Trabajo práctico:
Obtendrá todos los enlaces con las cosas adicionales (como “../” y “#” en el inicio del enlace) [19659002]
En la imagen anterior, tomamos la condición if donde se encuentra el enlace o puede decir que la cadena comienza con el inicio “../” con la posición 3 de la cadena usando el método slice y las cosas adicionales como "#", lo cual no es útil para nosotros, por eso no lo incluimos en nuestra salida y usamos la función len () también para imprimir la cadena en el último y con el prefijo de nuestra página web también se agregan para crear el enlace. En su caso, puede usar su propia condición de acuerdo con su salida. Ahora puede ver que obtenemos más de un enlace usando if condición. Obtenemos tantos enlaces, pero también hay un problema que es que no estamos recibiendo los enlaces que comienzan con "/". Para obtener estos enlaces, también tenemos que hacer más cambios en nuestro código para ver qué debemos hacer. Por lo tanto, tenemos que agregar la condición elif también con la condición de "/" y aquí también deberíamos dar la condición de "#". De lo contrario, obtendremos cosas adicionales nuevamente en la imagen de abajo. Hemos hecho esto.
Después de poner esto y su condición en nuestro programa para encontrar todos los enlaces en nuestra página web en particular. Tenemos los enlaces sin ningún error que puede ver en la siguiente imagen. Cómo aumentamos nuestros números de enlaces desde el programa sin la condición if y elif.
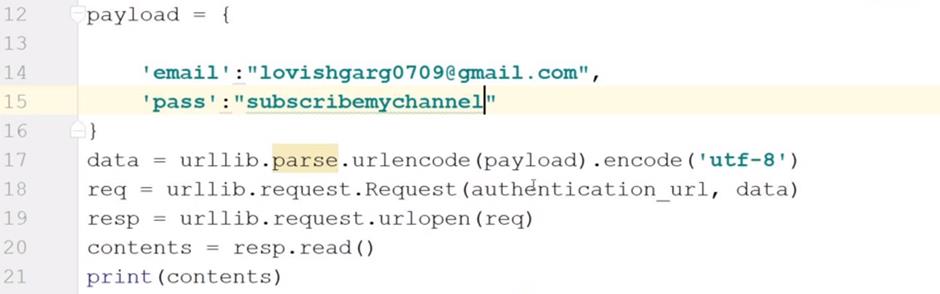
De esta forma podemos obtener todos los enlaces del texto de nuestra página o sitio web en particular, en el que puede encontrar los enlaces. forma de canal de youtube también. Nota: Si tiene algún problema para obtener los enlaces, cambie las condiciones en el programa como lo he hecho con mi problema que puede usar como su requisito. Así que hemos hecho cómo podemos obtener los enlaces de cualquier página web o canal de YouTube. 3. Iniciar sesión en Facebook a través de Web ScrapingIntroducción En este método, podemos iniciar sesión en cualquier cuenta de Facebook utilizando Scraping. Condiciones: Cómo podemos usar este escarpado en Facebook porque seguridad de Facebook no podemos hacerlo directamente. Por lo tanto, no podemos iniciar sesión en Facebook directamente. Deberíamos hacer cambios en la URL de Facebook, como deberíamos usar m.facebook.com o mbasic.facebook.com url en lugar de www.facebook.com porque Facebook tiene un alto nivel de seguridad, no podemos descartar datos directamente. Comencemos a desechar. Este Es la página web de m.facebook.com URL Empecemos con python. Entonces, primero importe todos estos módulos: import http.cookiejar import urllib.request peticiones de importación [1965902020] import bs4 Luego, crea un objeto y usa el método cookiejar que te proporciona la cookie en tu buscador python. Crea otro objeto conocido como abridor y asigna el solicite el método. Nota: haga todas las cosas bajo su riesgo, no piratee la identificación de otra persona o de otra manera.
|











I cannot thank you enough for the blog.Thanks Again. Keep writing.
ReplyDeleteOracle rac online training
Oracle rac training
Oracle SCM online training
Oracle SCM training
Oracle SOA online training
Oracle SOA training
Oracle sql plsql online training
Oracle sql plsql training