
En este post quiero explorar los costos de los hilos en las máquinas modernas de Linux,
Tanto en términos de tiempo como de espacio. El contexto de fondo es el diseño de alta carga.
servidores concurrentes, donde usar subprocesos es uno de los esquemas comunes .
Aviso importante: no es mi objetivo proporcionar una opinión en los subprocesos
Debate de modelos frente a eventos. En última instancia, ambas son herramientas que funcionan bien en
Algunos escenarios y menos bien en otros. Dicho esto, una de las mayores críticas.
de un modelo basado en subprocesos es el costo; comentarios como "pero los cambios de contexto son
caro! "o" pero mil hilos se comen toda tu memoria RAM ", y lo hago
la intención de estudiar los datos subyacentes a tales reclamos en más detalle aquí. Lo haré
esto mediante la presentación de múltiples ejemplos de código y programas que facilitan la
explore y experimente con estas medidas.
Subprocesos de Linux y NPTL
En la oscuridad, la antigüedad anterior a la versión 2.6, el kernel de Linux no tenía mucho
soporte específico para hilos, y fueron más o menos hackeados en la parte superior de
proceso de soporte. Antes de futexes no había ningún dedicado
solución de sincronización de baja latencia (se realizó mediante señales); tampoco fue
hay un buen uso de las capacidades de los sistemas de múltiples núcleos.
La Biblioteca de subprocesos POSIX nativa (NPTL) fue propuesta por Ulrich Drepper e Ingo
Molnar de Red Hat, e integrado en el kernel en la versión 2.6, circa 2005.
Recomiendo encarecidamente leer su papel de diseño . Con NPTL, creación de hilos.
el tiempo se hizo 7 veces más rápido, y la sincronización también se hizo mucho más rápida
Para el uso de futexes. Los hilos y procesos se hicieron más ligeros, con
fuerte énfasis en hacer un buen uso de procesadores multi-core. Esto aproximadamente
coincidió con un programador mucho más eficiente que hizo malabarismos muchos
Los hilos en el kernel de Linux son aún más eficientes.
A pesar de que todo esto sucedió hace 13 años, el espíritu de NPTL todavía es
Fácilmente observable en algunos códigos de programación del sistema. Por ejemplo, muchos hilos y
las rutas relacionadas con la sincronización en glibc tienen nptl en su nombre.
Subprocesos, procesos y la llamada del sistema de clones
Originalmente, esto fue parte de este artículo más grande , pero fue
Me demoro demasiado, así que me separé de una publicación separada sobre lanzando procesos Linux
e hilos con clon ,
donde puede conocer la llamada al sistema clone y algunas mediciones de cómo
es costoso lanzar nuevos procesos y subprocesos.
El resto de este post asumirá que es información familiar y se enfocará
sobre el cambio de contexto y el uso de la memoria.
¿Qué sucede en un cambio de contexto?
En el kernel de Linux, esta pregunta tiene dos partes importantes:
- Cuando ocurre un cambio de kernel
- Cómo sucede
Lo siguiente trata principalmente con (2), asumiendo que el núcleo ya ha decidido
cambiar a un hilo de usuario diferente (por ejemplo, porque la ejecución actual
el subproceso pasó a la espera de E / S).
Lo primero que sucede durante un cambio de contexto es un cambio al modo kernel,
ya sea a través de una llamada explícita al sistema (como escriba en algún archivo o canalización)
o una interrupción por temporizador (cuando el núcleo precede a un hilo de usuario cuyo intervalo de tiempo
ha expirado). Esto requiere guardar los registros del hilo del espacio de usuario y
saltando al código del kernel.
A continuación, el programador se activa para descubrir qué hilo debería ejecutarse a continuación. Cuando
Sabemos qué hilo se ejecuta a continuación, existe la importante contabilidad de virtual
memoria para cuidar; Las tablas de páginas del nuevo hilo deben ser cargadas en
memoria, etc.
Finalmente, el kernel restaura los registros del nuevo hilo y el control de cedes regresa
al espacio del usuario.
Todo esto lleva tiempo, pero ¿cuánto tiempo, exactamente? Te animo a que leas un poco
recursos adicionales en línea que tratan con esta pregunta, y tratan de correr
puntos de referencia como lm_bench ; lo que sigue es
mi intento de cuantificar el tiempo de cambio de subprocesos.
¿Qué tan caros son los cambios de contexto?
Para medir cuánto tiempo lleva cambiar de dos subprocesos, necesitamos un punto de referencia
que deliberadamente activa un cambio de contexto y evita hacer demasiado trabajo en
Además de eso. Esto sería medir solo el costo directo del interruptor ,
cuando en realidad hay otro costo: el indirecto que incluso podría
ser mas grande Cada hilo tiene algún conjunto de memoria de trabajo, todos o algunos de los cuales
está en el caché; cuando cambiamos a otro hilo, todos estos datos de caché se convierten en
innecesariamente y se vacía lentamente, reemplazado por los datos del nuevo hilo. Frecuente
los conmutadores de ida y vuelta entre los dos hilos causarán una gran cantidad de tales
En mis puntos de referencia no estoy midiendo este costo indirecto, porque es bastante
Difícil de evitar en cualquier forma de multitarea. Incluso si "cambiamos" entre
diferentes controladores de eventos asíncronos dentro del mismo hilo, probablemente
tienen diferentes conjuntos de trabajo de memoria e interferirán con el caché del otro
uso si esos conjuntos son lo suficientemente grandes. Recomiendo encarecidamente ver este
charla sobre fibras donde explica un ingeniero de Google
Su metodología de medición y también cómo evitar demasiados interruptores indirectos.
costos al asegurarse de que las tareas estrechamente relacionadas se ejecuten con la localidad temporal.
Estos ejemplos de código
mida los gastos generales de conmutación de contexto usando dos técnicas diferentes:
- Una tubería que es utilizada por dos hilos para hacer ping-pong a una pequeña cantidad de datos.
Cada leído en la tubería bloquea el hilo de lectura, y el kernel cambia
al hilo de escritura, y así sucesivamente. - Una variable de condición utilizada por dos hilos para señalar un evento entre sí.

Hay factores adicionales que dependen del tiempo de cambio de contexto; por ejemplo,
en una CPU multi-core, el núcleo ocasionalmente puede migrar un hilo entre núcleos
porque el núcleo que un hilo ha estado usando anteriormente está ocupado. Mientras esto
ayuda a utilizar más núcleos, tales interruptores cuestan más que permanecer en el mismo núcleo
(de nuevo, debido a los efectos de caché). Los puntos de referencia pueden intentar restringir esto ejecutando
con tasket fijando afinidad a un núcleo, pero es importante mantenerse en
Ten en cuenta que esto solo modela un límite inferior.
Al usar las dos técnicas, obtengo resultados bastante similares:
1.2 y 1.5 microsegundos por cambio de contexto, representando solo el directo
costo, y la fijación a un solo núcleo para evitar los costos de migración. Sin fijar,
El tiempo de conmutación sube a ~ 2.2 microsegundos. Estos números son en gran parte
De acuerdo con los informes en la charla sobre fibras mencionados anteriormente, y también con
otros puntos de referencia encontrados en línea (como lat_ctx de lmbench ).
¿Qué significa esto en la práctica?
Así que tenemos los números ahora, pero ¿qué significan? ¿Es 1-2 nos lleva mucho tiempo? Como yo
he mencionado en el post sobre gastos generales de lanzamiento ,
una buena comparación es memcpy que toma 3 us para 64 KiB en el mismo
máquina. En otras palabras, un cambio de contexto es un poco más rápido que copiar 64 KiB
de memoria de una ubicación a otra.
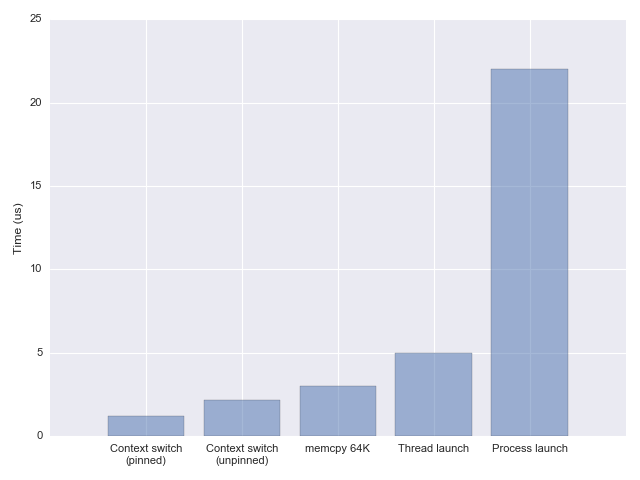
1-2 no es mucho tiempo por ninguna medida, excepto cuando realmente está intentando
optimice para latencias extremadamente bajas o cargas altas.
Como ejemplo de una carga artificialmente alta, aquí hay otro punto de referencia
que escribe un mensaje corto en una tubería y espera leerlo de otro
tubo. En el otro extremo de los dos tubos hay un hilo que hace eco de uno en el
otro.
Ejecutando el punto de referencia en la misma máquina que usé para medir el cambio de contexto
veces, obtengo ~ 400,000 iteraciones por segundo (esto es con tasket para fijar
a un solo núcleo). Esto tiene mucho sentido dadas las medidas anteriores,
porque cada iteración de esta prueba realiza dos cambios de contexto, y en 1.2 us
por interruptor, esto es 2.4 us por iteración.
Podrías afirmar que los dos subprocesos compiten por la misma CPU, pero si no lo hago
fije el punto de referencia a un solo núcleo, el número de iteraciones por segundo
mitades . Esto se debe a que la gran mayoría del tiempo en este índice de referencia se invierte.
en el kernel cambiando de un hilo a otro, y las migraciones centrales
que se producen cuando no está fijado en gran medida la pérdida de (el mínimo)
paralelismo.
Sólo por diversión, reescribí el mismo punto de referencia en Go ;
Dos goroutines ping-ponging mensaje corto entre ellos a través de un canal. los
el rendimiento que se logra es dramáticamente más alto: alrededor de 2.8 millones
iteraciones por segundo, lo que lleva a una estimación de ~ 170 ns cambiando entre
goroutines. Dado que el cambio entre goroutines no requiere un real
cambio de contexto del kernel (o incluso una llamada del sistema), esto no es demasiado sorprendente. por
comparación, las fibras de Google utilizan un nuevo Linux
llamada al sistema que puede cambiar entre dos tareas casi al mismo tiempo,
incluyendo el tiempo del núcleo.
Una advertencia: los puntos de referencia tienden a tomarse muy en serio. Por favor tome esta
uno solo por lo que demuestra: una carga de trabajo en gran parte sintética utilizada para
ahorre en el costo de algunas primitivas de concurrencia fundamentales.
Recuerde: es bastante improbable que la carga de trabajo real de su tarea sea
insignificante en comparación con el cambio de contexto 1-2 us; Como hemos visto, incluso una modesta.
memcpy lleva más tiempo. Cualquier tipo de lógica de servidor, como los encabezados de análisis,
Es probable que la actualización del estado, etc., tome órdenes de magnitud más tiempo. Si hay
Una conclusión para recordar de estas secciones es que el cambio de contexto en lo moderno
Los sistemas Linux son súper rápido .
Uso de memoria de subprocesos
Ahora es el momento de discutir la otra sobrecarga de una gran cantidad de subprocesos:
memoria. A pesar de que todos los hilos en un proceso comparten su, hay
Todavía hay áreas de la memoria que no se comparten. En la publicación sobre el clon
hemos mencionado tablas de páginas en el kernel, pero estas son comparativamente pequeñas.
Un área de memoria mucho más grande que es privada para cada subproceso es la pila .
El tamaño predeterminado de la pila por subproceso en Linux suele ser de 8 MiB, y podemos verificar
qué es invocando ulimit :
Para ver esto en acción, comencemos una gran cantidad de hilos y observemos la
Uso de memoria del proceso. Esta muestra
lanza 10,000 hilos y duerme un poco para observar su uso de memoria
Con herramientas externas. Usando herramientas como arriba (o preferiblemente htop ) vemos
que el proceso utiliza ~ 80 GiB de memoria virtual con aproximadamente 80 MiB de
memoria residente . ¿Cuál es la diferencia y cómo puede usar 80 GiB de memoria?
en una máquina que solo tiene 16 disponibles?
Virtual vs. Resident memory
Un breve intervalo sobre lo que significa memoria virtual. Cuando un programa de Linux asigna
memoria (con malloc ) o de lo contrario, esta memoria inicialmente no lo hace realmente
existe – es solo una entrada en una tabla que el sistema operativo guarda. Solo cuando el programa
en realidad accede a la memoria es la memoria RAM de respaldo que se encuentra; esto es lo que
La memoria virtual es todo acerca de.
Por lo tanto, el "uso de memoria" de un proceso puede significar dos cosas: cuánto
memoria virtual que usa en general, y cuánta memoria real utiliza. Mientras
lo primero puede crecer casi sin límites, lo segundo está obviamente limitado a
La capacidad de RAM del sistema (con el intercambio al disco es el otro mecanismo de
memoria virtual para ayudar aquí si el uso crece por encima del lado de la memoria física).
La memoria física real en Linux se llama memoria "residente", porque es
actualmente residente en RAM.
Hay una buena discusión de StackOverflow
de este tema; aquí me limitaré a un simple ejemplo:
int main ( int argc char ** argv [19659048]) {
report_memory ( "comenzado" );
int N = 100 * ] [ ] 100 * 1024 ;
int * m = malloc ( N tamaño tamaño ] ( int ));
escape ( m );
report_memory ( "después de malloc" ); [19659090] para ( int i = 0 ; i < N ++ ++ ] i ) {
m [ i ] = i ;
}
report_memory () "después del toque" );
printf ( "presione E NTER n ");
( void ) fgetc ( stdin
![) </span> <span class=]() return
return
![] 0 </span><span class=]() ;
}
;
}
Este programa comienza con la asignación de 400 MiB de memoria (asumiendo un tamaño int de
4) con malloc y más tarde "toca" esta memoria escribiendo un número en
cada elemento de la matriz asignada. Reporta su propio uso de memoria en cada
paso: consulte el ejemplo de código completo
para el código de reporte. Aquí está la salida de una ejecución de muestra:
$ ./malloc-memusage
inicio: max RSS = 4780 kB; tamaño vm = 6524 kB
después de malloc: max RSS = 4780 kB; tamaño vm = 416128 kB
después del toque: max RSS = 410916 kB; tamaño vm = 416128 kB
Lo más interesante de observar es cómo vm size permanece igual entre
el segundo y tercer paso, mientras que max RSS crece desde el valor inicial hasta
400 MiB. Esto es precisamente porque hasta que no tocamos la memoria, es totalmente
"virtual" y en realidad no se cuenta para el uso de RAM del proceso.
Por lo tanto, distinguir entre memoria virtual y RSS en uso realista es
muy importante – es por esto que el ejemplo de inicio de hilos de la sección anterior
podría "asignar" 80 GiB de memoria virtual mientras tiene solo 80 MiB de residente
Volver a la sobrecarga de memoria para subprocesos
Como hemos visto, se creó un nuevo subproceso en Linux con 8 MiB de espacio de pila, pero
esto es memoria virtual hasta que el hilo realmente lo usa. Si el hilo en realidad
utiliza su pila, el uso de memoria residente aumenta dramáticamente para una gran cantidad de
trapos. He agregado una opción de configuración al programa de muestra que lanza una
gran cantidad de hilos; con él habilitado, la función de hilo en realidad utiliza
Apilar la memoria y desde el informe RSS es fácil observar los efectos.
Curiosamente, si hago que cada uno de los 10,000 hilos use 400 KiB de memoria, el RSS total
No es 4 GiB sino alrededor de 2.6 GiB. Sospecho que esto es porque el sistema operativo no lo hace
en realidad, mantenga esta cantidad de subprocesos paginados en cualquier momento – la memoria de algunos subprocesos se pone
paginado hasta que los subprocesos estén activos.
¿Cómo controlamos el tamaño de pila de los subprocesos? Una opción es usar el ulimit
comando, pero una mejor opción es con la API pthread_attr_setstacksize . los
este último se invoca mediante programación y llena una estructura pthread_attr_t
Eso se pasa a la creación de hilos. La pregunta más interesante es qué debería
el tamaño de pila se debe establecer en?
Como hemos visto anteriormente, solo crear una pila grande para un hilo no lo hace
Se come automáticamente toda la memoria de la máquina, no antes de que la pila esté
siendo utilizado. Si nuestros hilos realmente usan grandes cantidades de memoria de pila, esto es
un problema, porque esto limita severamente la cantidad de subprocesos que podemos ejecutar
concurrentemente Tenga en cuenta que esto no es realmente un problema con hilos, sino con
concurrencia Si nuestro programa utiliza algún enfoque basado en eventos para la concurrencia y
cada manejador usa una gran cantidad de memoria, todavía tendríamos el mismo problema.
Si la tarea no usa mucha memoria, ¿qué deberíamos configurar la pila?
tamaño para? Las pilas pequeñas mantienen el sistema operativo seguro – un programa desviado puede entrar en un
La recursión infinita y una pequeña pila asegurarán que se elimine antes. Además,
La memoria virtual es grande pero no ilimitada; especialmente en sistemas operativos de 32 bits, podríamos
no tiene 80 GiB de espacio de direcciones virtuales para el proceso, por lo que una pila de 8 MiB para
10.000 hilos no tiene sentido. Hay una compensación aquí, y el valor predeterminado elegido
Linux de 32 bits es 2 MiB; el espacio de direcciones virtuales máximo disponible es 3 GiB,
por lo que esto impone un límite de ~ 1500 hilos con la configuración predeterminada. En 64 bits
Linux, el espacio de direcciones virtuales es mucho más grande, por lo que esta limitación es menor
serio (aunque otros límites entran en juego, en mi máquina el número máximo de
los hilos que el sistema operativo permite que un proceso comience es de aproximadamente 32K).
Por lo tanto, creo que es más importante concentrarse en la cantidad de memoria real de cada uno.
está utilizando una tarea simultánea que en el límite de tamaño de pila del sistema operativo, ya que este
simplemente una medida de seguridad.
Conclusión
Los números informados aquí muestran una imagen interesante sobre el estado de Linux
rendimiento multi-hilo en 2018. Yo diría que los límites aún
existir: ejecutar un millón de subprocesos probablemente no tenga sentido; sin embargo,
los límites definitivamente han cambiado desde el pasado, y una gran cantidad de folclore de
La década de 2000 no se aplica hoy. En una máquina de múltiples núcleos carnosa con lotes
de RAM, podemos ejecutar fácilmente 10.000 subprocesos en un solo proceso hoy, en
producción. Como he mencionado anteriormente, es muy recomendable ver Google
charla sobre fibras ; a través de una cuidadosa puesta a punto
el kernel (y la configuración de pilas predeterminadas más pequeñas) Google puede ejecutar un pedido
de magnitud más subprocesos en paralelo.
Es muy obvio si esto es suficiente concurrencia para su aplicación
específico del proyecto, pero diría que para concurrencias más altas probablemente querría
Para mezclar en algún procesamiento asíncrono. Si 10.000 hilos pueden proporcionar suficiente
concurrencia: está de suerte, ya que este es un modelo mucho más simple: todo el código
dentro de los hilos es serial, no hay problemas con el bloqueo, etc.
No comments:
Post a Comment